И така, средата ви в Kubernetes (K8s) работи безпроблемно – приложенията са пуснати, капсулите се мащабират и всичко изглежда наред. Но сигурни ли сте, че под повърхността на конфигурацията ви не се натрупват неусетно технически дълг, пропуски в сигурността или оперативна неефективност?
Kubernetes се променя постоянно и без редовни прегледи неправилните конфигурации, остарелите зависимости и неоптимизираните ресурси могат да създадат рискове за сигурността, проблеми с производителността и оперативни затруднения. Правилният преглед на K8s не представлява попълване на контролен списък за съответствие; той трябва да установи какво работи, какво не работи и как да се коригира, преди проблемите да се задълбочат.
Това ръководство предоставя стъпки за практическа, структурирана оценка, която обхваща:
Инструменти за автоматизирани и базирани на данни прозрения
Често срещани пропуски и как да ги коригирате, преди да са причинили прекъсвания и оперативни проблеми
Стратегии за определяне на приоритети, така че да отделяте време за корекции с голямо въздействие
Накрая ще разполагате с ясна пътна карта за инспектиране и подобряване на средата ви в Kubernetes – без излишни подробности.
Защо средите в Kubernetes трябва да се преглеждат редовно
Kubernetes е създаден с цел мащабиране и гъвкавост, но това го прави податлив на скрити рискове. Дори и днес клъстерите ви да работят добре, без редовни прегледи може да се стигне до:
Уязвимости в сигурността – неправилно конфигурираният контрол на достъпа въз основа на роли (RBAC), отворените мрежови политики или остарелите изображения създават възможности за атаки.
Неефективност на разходите – прекомерната ресурсна обезпеченост или работните натоварвания „зомбита“ увеличават разходите за облака.
Оперативен риск – отклонението на конфигурацията, остарелите зависимости и нетестваните обновявания водят до нестабилност.
Как да извършим преглед на Kubernetes без догадки
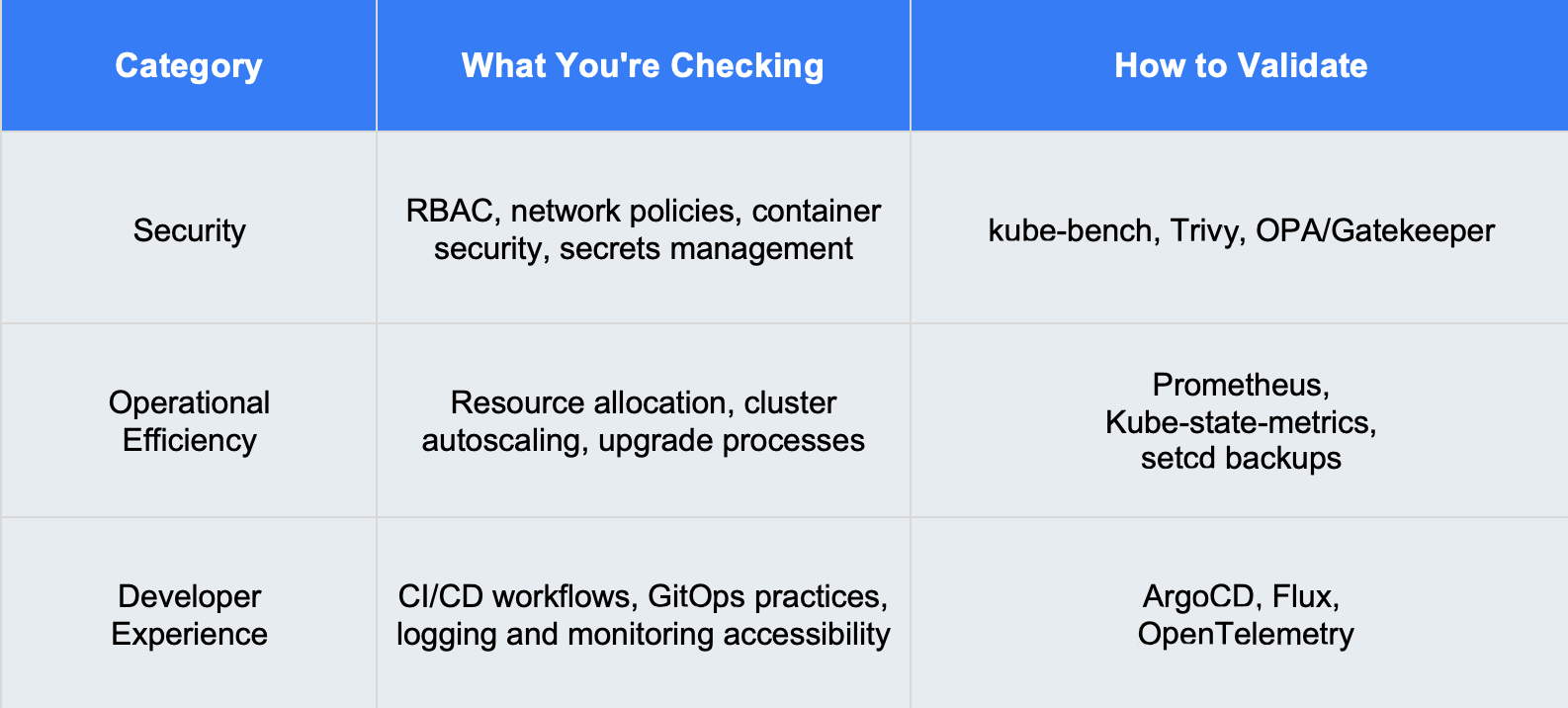
Добрият преглед дава отговор на ключови въпроси с категорични данни, а не с предположения. Трите основни категории за оценка на Kubernetes са:
Ключови инструменти за преглед на Kubernetes
Проверки на сигурността и конфигурацията
kube-bench – спазване на референтни стойности на Центъра за информационна сигурност (CIS) за Kubernetes.
Trivy – сканира изображения и клъстерни конфигурации за уязвимости.
Polaris – открива неправилни конфигурации, като например липсващи ограничения на ресурсите.
OPA/Gatekeeper – прилага политики (напр. забрана на главни контейнери, задължителни етикети).
Наблюдение и мониторинг на производителността
Prometheus и Grafana – основен пакет за мониторинг на показателите на клъстерите.
Jaeger – разпределено проследяване за анализ на потоците от заявки.
Parca – непрекъснато профилиране за оптимизиране на използването на ресурсите.
Отклонение на конфигурацията и GitOps
Kyverno или OPA – открива и налага спазването на политики.
ArgoCD или Flux – осигурява запазването на синхрон на инфраструктурата, дефинирана от Git.
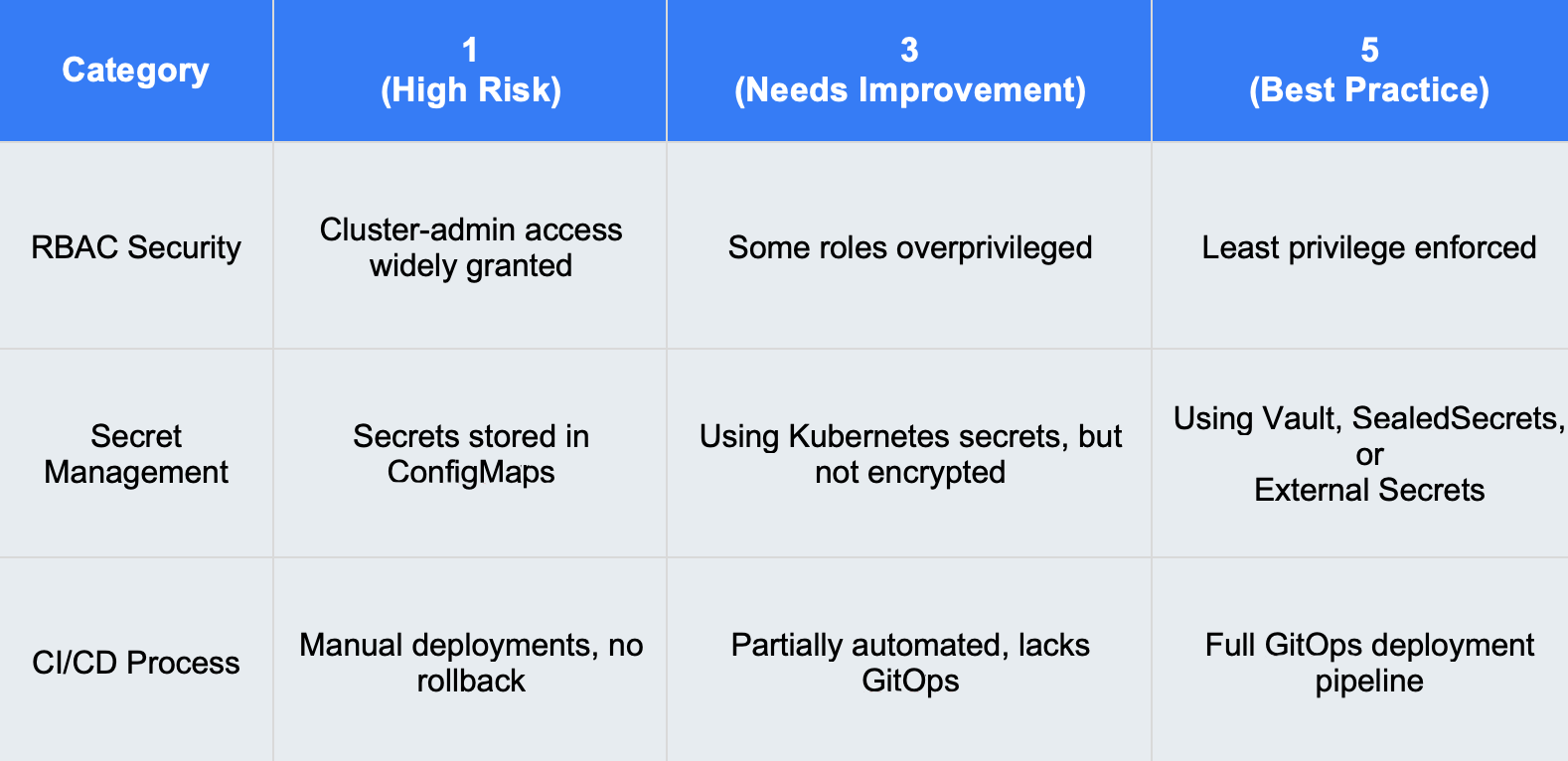
Картата с резултати на Kubernetes: Структурирана рамка за оценка
След като съберете данни, как да измерите състоянието на средата си? Използвайте матрица за оценяване, за да подредите ключовите области от 1 (висок риск) до 5 (най-добра практика).
5-те най-често срещани слабости на Kubernetes (и как да ги коригираме)
Въпреки че всяка среда в Kubernetes е различна, някои неправилни конфигурации и оперативни пропуски се появяват многократно. Ако тези слабости не бъдат отстранени, те могат да доведат до уязвимости в сигурността, оперативна неефективност и проблеми с производителността. По-долу са представени пет от най-често срещаните проблеми и как да ги разрешите ефективно.
1. RBAC е прекалено толерантен
Проблем: Много среди в Kubernetes предоставят прекомерни разрешения, като често задават твърде широки роли на администратори на клъстери. Това води до ненужни рискове за сигурността, като увеличава вероятността от атаки с увеличаване на привилегиите или неволни неправилни конфигурации.
Решение: Приложете принципа на най-малките привилегии (PoLP), като дефинирате подробни политики за контрол на достъпа въз основа на роли (RBAC). Ограничете ролите за целия клъстер и използвайте роли, ограничени до именни пространства, когато това е възможно. Редовно проверявайте обвързването на ролите с инструменти като rbac-lookup или с нативния „kubectl auth can-I“, за да идентифицирате прекомерни разрешения.
2. Лошо управление на тайната информация
Проблем: Поверителната информация, като например идентификационни данни за бази данни и API ключове, често се съхранява в открит текст в ConfigMaps или Kubernetes Secrets, без да е шифрована. Тайната информация в Kubernetes Secrets по подразбиране се кодира само чрез Base64, което не представлява механизъм за сигурност.
Решение: Съхранявайте и управлявайте тайната информация по сигурен начин, като използвате запечатани тайни низове, HashiCorp Vault или External Secrets Operator. Активирайте шифроването в покой за Kubernetes Secrets и използвайте контрол на достъпа, за да ограничите неупълномощеното извличане.
3. Стратегиите за обновяване и архивиране са лоши
Проблем: Много екипи отлагат обновяванията на Kubernetes поради опасения от прекъсване на работата или нарушаване на работните натоварвания, като така оставят клъстерите да работят с остарели, неподдържани версии. Освен това стратегиите за архивиране често са непълни и обхващат данните на приложенията, но не и etcd (хранилището за данни на контролната плоскост на Kubernetes).
Решение: Приложете стратегия за постепенно обновяване и тествайте новите версии в симулационна производствена среда, преди да ги внедрите в производството. Автоматизирайте архивирането на данните на приложенията и etcd и проверявайте редовно процедурите за възстановяване. Използвайте инструменти като Velero за възстановяване след бедствие.
4. Отклонението на конфигурацията се случва неусетно
Проблем: Ръчните промени, направени директно в действащ клъстер на Kubernetes, могат да доведат до отклонение на конфигурацията, при което текущото състояние се разминава с предвидената конфигурация. Това води до непредсказуемо поведение и усложнява отстраняването на проблеми.
Решение: Прилагайте практиките на GitOps с помощта на инструменти като ArgoCD или Flux, като се уверите, че всички промени се управляват чрез инфраструктура като код (IaC) с контролирана версия. Редовно сканирайте за отклонение с помощта на Kyverno или OPA и задайте предупреждения за неупълномощени промени.
5. Каналите за непрекъсната интеграция/внедряване (CI/CD) забавят разработчиците
Проблем: Неефективните канали за внедряване причиняват затруднения за разработчиците, което води до по-бавно въвеждане на издания и намалена производителност. Често срещаните проблеми включват стъпки за ръчно одобрение, непоследователни среди и липса на механизми за връщане в предишно състояние.
Решение: Стандартизирайте и автоматизирайте внедряванията, като използвате техники за прогресивна доставка, като например внедрявания на две идентични среди (blue-green deployment), издания за ограничен брой потребители (canary release) или отметки за функции (feature flag). Внедрете CI/CD канали на самообслужване с инструменти като ArgoCD и Tekton, които позволяват на разработчиците да внедряват безопасно, като същевременно има поставени предпазни бариери.
От преглед към действие: Коригиране, определяне на приоритети и проследяване на напредъка
Определяне на приоритетните корекции въз основа на риска и усилията
ЧЗВ
Колко често трябва да преглеждам средата си в Kubernetes? Поне веднъж на тримесечие, но при високорисковите клъстери (обработващи поверителни данни) може да са необходими ежемесечни прегледи.
Кой е най-лесният начин да започна преглед на Kubernetes? Извършете проверки с kube-bench, Trivy и Prometheus, за да получите първоначални прозрения.
Коя е най-голямата грешка в прегледите на Kubernetes? Пренебрегването на RBAC и неправилното управление на тайната информация. Това са високорискови области.
Окончателни разсъждения
Като следвате тази структурирана оценка, ще се погрижите за скритите рискове, ще оптимизирате ресурсите и ще поддържате безпроблемната работа на средата си в Kubernetes.
Следете ни, за да научите кога се нуждаете от преглед на Kubernetes и за какви ранни предупредителни сигнали да внимавате!
Открийте как Mainstream може да подобри вашия бизнес.
Свържете се с нас на business.bg@mainstream.bg или попълнете нашата контактна форма.
Kak kompaniite mogat da namalyat finansoviya risk ot oblachnite tekhnologii, praktichen podkhod za po-dobŭr kontrol na razkhodite, upravlenie i vzemane na resheniya.
Научете как стратегиите за архивиране и възстановяване след бедствия помагат за спазване на директивата NIS2 и засилват киберсигурността и непрекъснатостта на бизнеса.
This article explores how organizations can ensure business continuity and build resilience through backup, disaster recovery, and cyber risk management to comply with the stringent requirements of the NIS2 Directive.